The 4-Step Core Processing Architecture
🛠️ Step 1: Deep Artifact Ingestion
Users feed the engine authentic text or audio samples that capture their core literary essence. The multi-modal processing layer natively digests .txt, .doc, .docx, .mp3, .wav, and .pdf formats up to 250MB. Whether it is a past manuscript chapter, a transcribed keynote lecture, or a series of personal emails, the platform prepares the material for stylistic extraction.
🔍 Step 2: The 72-Point Forensic Voice Audit
Our specialized Linguistic Profiler breaks down the source material against up to 72 unique parameters of language expression. This deep-level evaluation goes far beyond simple keywords to codify sentence length variance, syntax rhythms, metaphor distributions, emotional baselines, and hidden structural rules. The results are compiled into a permanent, secure cryptographic identity tag called your Voice DNA Code.
🔄 Step 3: Algorithmic Transformation (Automated Ghostwriting)
When you input a rough draft, a bulleted list of concepts, or generic AI text , the core transformation model acts as a professional ghostwriter. It processes your input raw material directly through your unique Voice DNA ruleset, updating the text structure, sentence cadences, and word usage. The platform delivers high-quality rewritten text completely clean of any robotic preamble or conversational AI filler.
🎛️ Step 4: Multi-Dimensional Slider Refinement
Final output adjustments are made via user-controlled web sliders:
Formality Slider (-5 to +5): Instantly adjusts the text formatting back and forth from casual personal chat to boardroom-ready corporate communication without altering your personal voice profile.
Reading Level Slider (4th to 16th Grade): Adjusts vocabulary and phrase complexity to match target audiences, defaulting to a highly readable 9th-grade level for quick web scannability.
Additional Custom Instruction Box: A free-text field that integrates explicit text modifiers (e.g., “remove passive language,” “make it friendlier”) into the active model generation cycle.
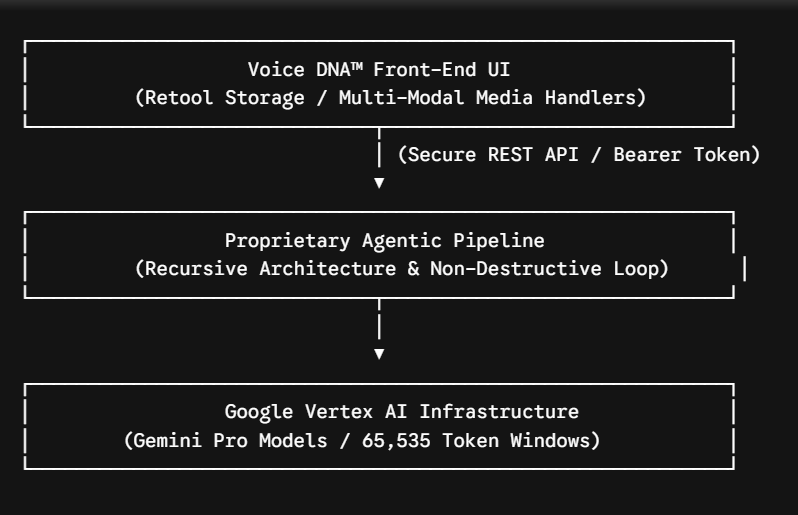
🔬 The Structural Technology Stack & Technical Moat
Voice DNA™ maintains an advanced cloud setup built directly on Google Vertex AI utilizing Gemini Pro models. This stack leverages huge processing windows and enterprise-level compliance to analyze and run long-form documents up to full-length books.
Recursive Processing Upgrade: Moving beyond linear steps where rewrites just build on prior output , our updated
Recursive Architecture forces the engine to check back with your baseline source material and instructions for every new piece of text generated.
Non-Destructive Loop Protocol: Our custom pipeline runs a fast “Go Back” command that allows rapid testing of tone tweaks without resetting your system session.
Backend Engineering Metrics: All system queries are configured with a generous 10-minute timeout for deep language parsing. Model parameters are fixed at a temperature of 0.8 to maximize creative personal flow while maintaining strict rule adherence , outputting up to a massive 65,535 tokens per single request.
📜 Architectural Process Flowchart (Provisional Patent Summary)
Our technical data handling is protected via patent-pending architectures verified under our USPTO provisional application guidelines:
Stage One: Data Input: Multi-modal text or audio stream collection via application interface or automated data pipelines.
Stage Two: Data Analysis: Analytical evaluation across up to 72 dimensions, applying 30 separate indicator filters to identify narrative rules like point-of-view constraints.
Stage Three: Rule Generation: The system converts style analysis findings into distinct programmatic formatting instructions.
Stage Four: Algorithm Creation: System electronic storage securely saves and catalogs your custom profile for ongoing, repeatable use.
Stage Five: Rewrite Ingestion: Input of the new target material or transcriptions you wish to process.
Stage Six: Rule-Based Data Regeneration: Our core model applies the generated rules as hard parameters to ghostwrite your incoming content.
Stage Seven: Document Refinement: Dual-panel GUI layout display lets users run side-by-side style comparisons and review structural changes.